Big Data Solutions




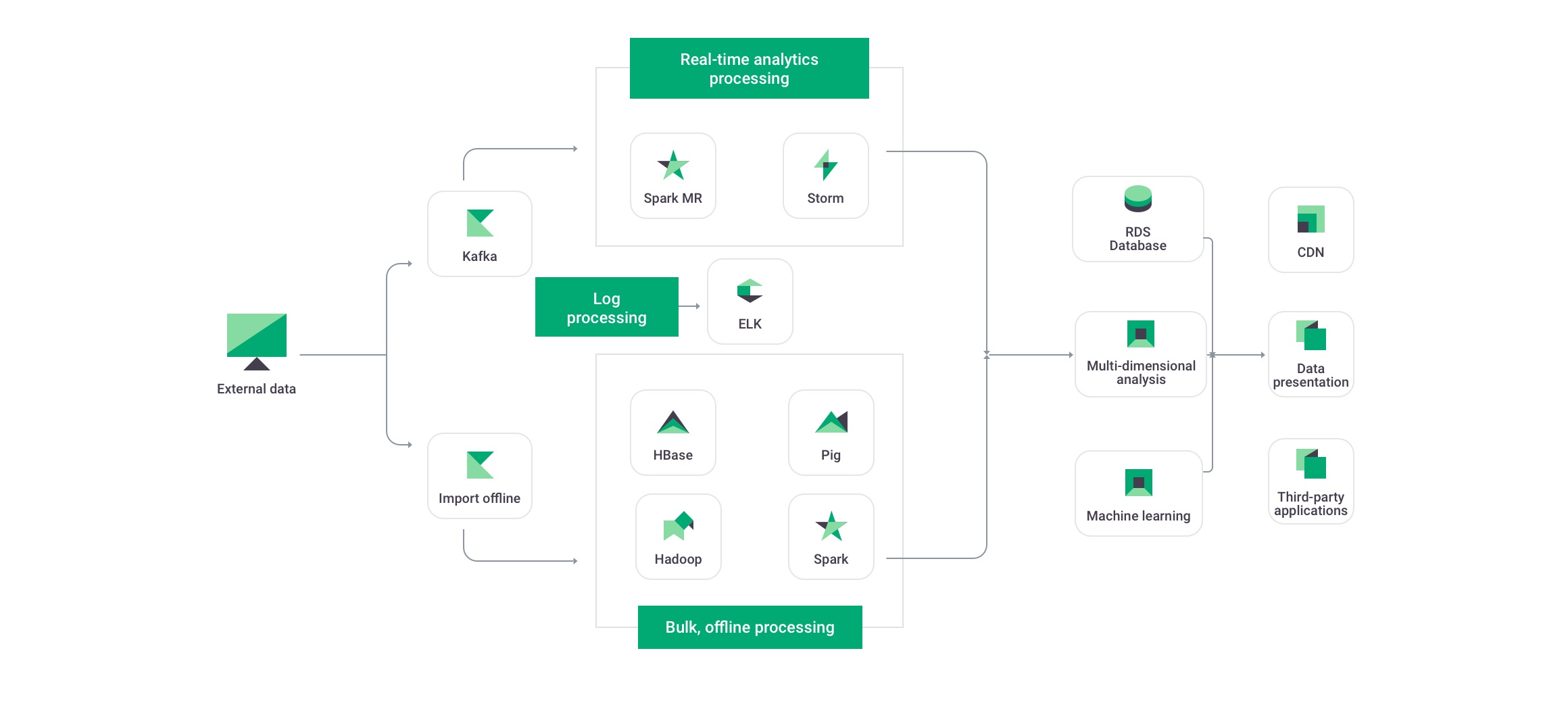
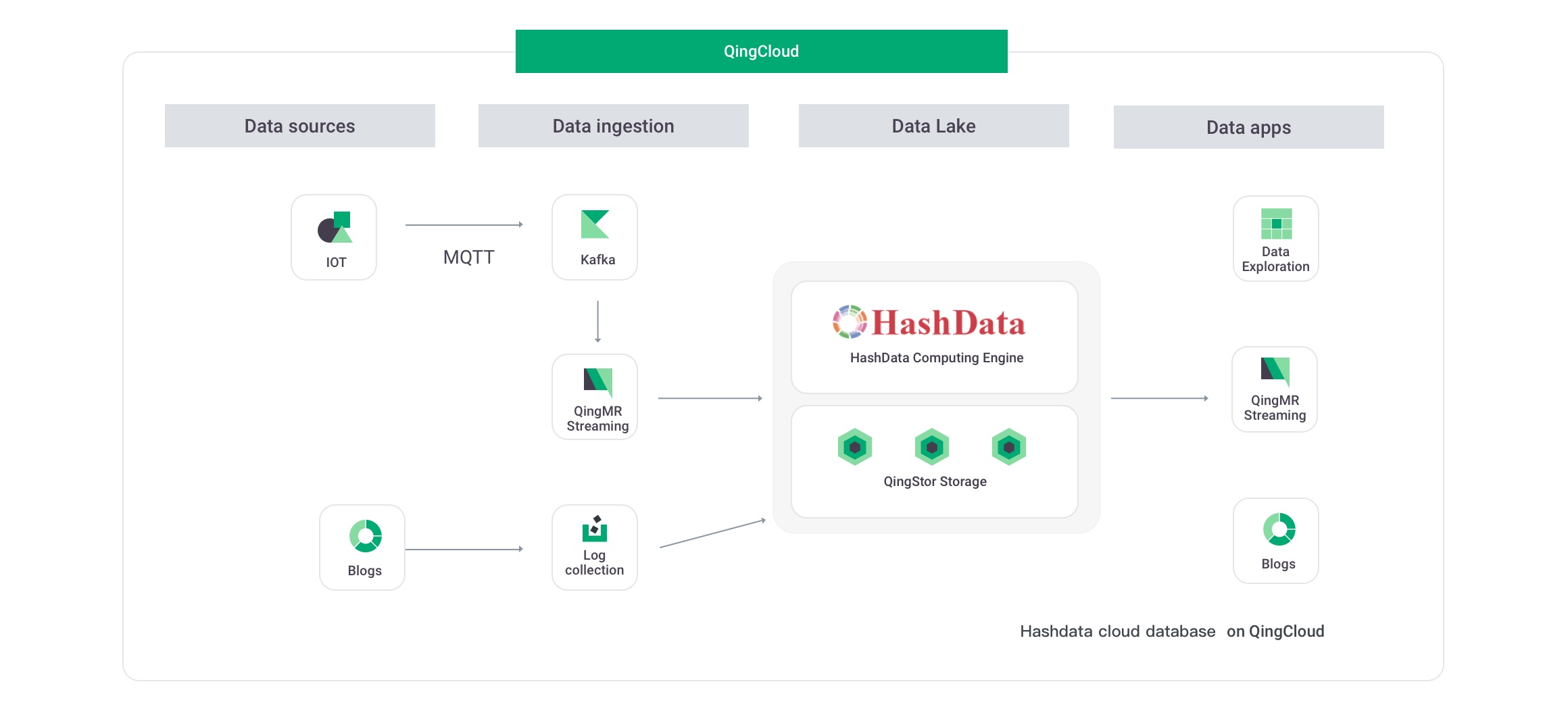
1. Compared with the architecture with coupled compute and storage, separation between them ensures query performance, greatly reducing server resource costs.
2. Secure and reliable storage services on the cloud enable data persistence to reach up to 99.999999999% and service availability to reach 99.99%.
3. Only 1/10 of storage costs for the traditional solution are required while the data query performance is ensured, greatly reducing IT costs.

